 YOLOv8 目标检测及图片裁剪
YOLOv8 目标检测及图片裁剪
# 前言
之前我们已经训练了识别是否佩戴口罩的模型文件,可以有效识别人群是否口罩,本文将会讲解如何将识别到的目标裁剪出来
# 目标识别
需要指定 save_txt=True,保存数据标注文件 txt
yolo predict model=runs/detect/train26/weights/best.pt source=ultralytics/assets/mask save_txt=True
1
查看标注文件目录及文件格式
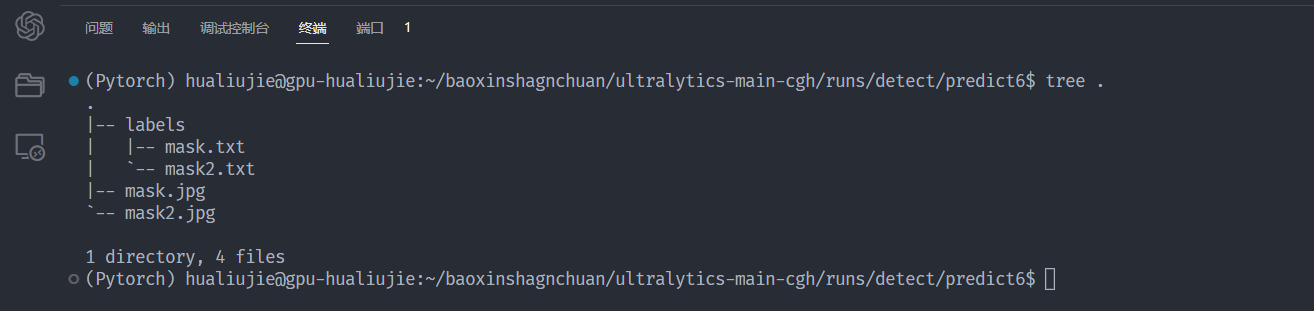
# 坐标转换
数据标注文件中格式(除类别之外都是归一化之后的值)
w:图片像素宽度
h:图片像素高度
0 0.301826 0.367765 0.123616 0.229143
label x_center y_center _width _height
1
2
2
x1=(x_center-width/2) * w
x2=(x_center+width/2) * w
y1=(y_center-height/2) * h
y2=(y_center+height/2) * h
1
2
3
4
2
3
4
# 剪裁脚本
import os
from PIL import Image
import shutil
def findSingleFile(path):
# 创建 cutpictures 文件夹(先判断)
cutp = os.path.join(path, "cutpictures")
# 判断文件夹是否存在
if os.path.exists(cutp):
# 如果文件夹存在,先删除再创建
# 递归删除文件夹
shutil.rmtree(cutp)
os.makedirs(cutp)
else:
# 如果文件夹不存在,直接创建
os.makedirs(cutp)
for filename in os.listdir(path):
if not os.path.isdir(os.path.join(path,filename)):
# 无后缀文件名
filename_nosuffix = filename.split(".")[0]
# 文件后缀
file_suffix = filename.split(".")[1]
# print(filename_nosuffix)
img_path = os.path.join(path,filename)
label_path = os.path.join(path,'labels',filename_nosuffix+".txt")
# print(img_path)
# print(label_path)
# 生成裁剪图片(遍历 txt 每一行)eg: mask_0_1.jpg
# 0 裁剪的图片序号 1 类别序号
img = Image.open(img_path)
w, h = img.size
with open(label_path, 'r+', encoding='utf-8') as f:
# 读取txt文件中的第一行,数据类型str
lines = f.readlines()
# 根据空格切割字符串,最后得到的是一个list
for index, line in enumerate(lines):
msg = line.split(" ")
category = int(msg[0])
x_center = float(msg[1])
y_center = float(msg[2])
width = float(msg[3])
height = float(msg[4])
x1 = int((x_center - width / 2) * w) # x_center - width/2
y1 = int((y_center - height / 2) * h) # y_center - height/2
x2 = int((x_center + width / 2) * w) # x_center + width/2
y2 = int((y_center + height / 2) * h) # y_center + height/2
# print(x1, ",", y1, ",", x2, ",", y2, "," ,category)
# 保存图片
img_roi = img.crop((x1, y1, x2, y2))
save_path = os.path.join(cutp, "{}_{}_{}.{}".format(filename_nosuffix, index, category, file_suffix))
img_roi.save(save_path)
print("裁剪图片存放目录:", cutp)
def main():
import argparse
# 创建 ArgumentParser 对象
parser = argparse.ArgumentParser(description='输入目标检测裁剪目录')
# 添加参数
parser.add_argument('--dir', help='目录名', required=True)
# 解析命令行参数
args = parser.parse_args()
dir = args.dir
# print('目录参数:', dir)
findSingleFile(dir)
return
if __name__ == '__main__':
main()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
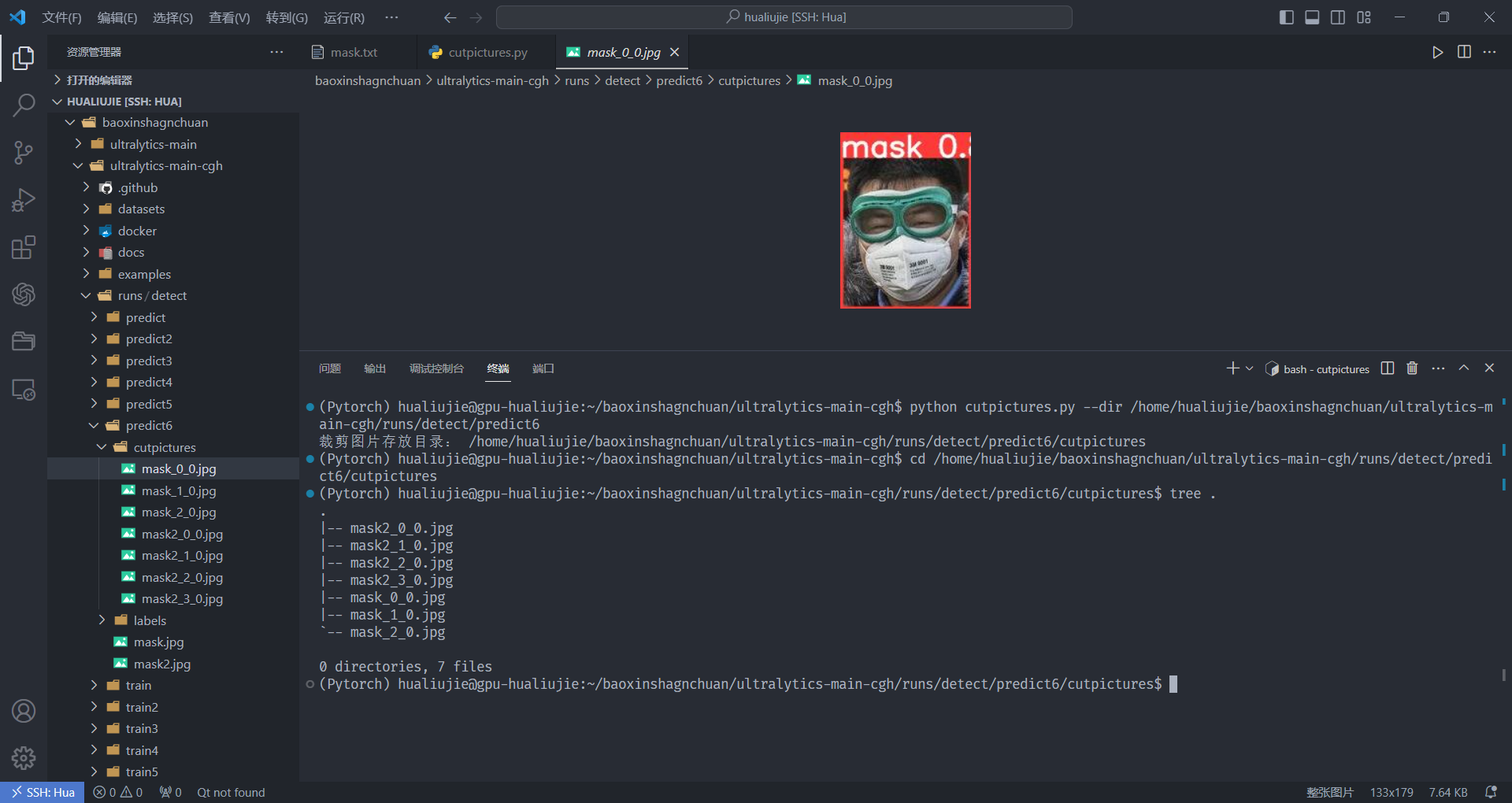
执行脚本(需要指定 --dir 目录位置参数)
python cutpictures.py --dir /home/hualiujie/baoxinshagnchuan/ultralytics-main-cgh/runs/detect/predict6
1
生成成功,文件名为 {无后缀文件名}_{裁剪图片序号}_{标签类别序号}
# 补充
我之后知道了 YOLOv8设置了专门的裁剪参数 save_crop,想要得到裁剪的图片只需要将该参数设置为 True 即可,但是上面做的并不是无用功,因为我们项目内部需要实现的功能是识别每个类别的精确位置,然后根据类别和位置裁剪,而不能笼统的根据类别
# 参考文章
利用yolov5进行目标检测,并将检测到的目标裁剪出来_目标检测_小脑斧ai吃肉-华为云开发者联盟 (csdn.net) (opens new window)
编辑 (opens new window)
上次更新: 2023/10/14, 10:01:13